Pseudoscientists in the Intelligent Design (ID) movement have long desired a track record of ID-related publications in peer-reviewed journals. Now Dembski and Marks are touting a new publication as a step in this direction. Reading the paper will be a disappointment to everyone who had hoped for any non-trivial results. The three things offered are:
(a) A simplistic notion of a search problem as consisting of nothing else than a search space and a target set .
(b) Definition of the endogenous probability as the probability of encountering a point in the target set using using uniformly random sampling. E.g. after search space queries, . Also introduced is the exogenous probability that a search algorithm will sample a point from the target set in at most queries. The ratio
measures how well suited the search algorithm is to the search problem, and is interpreted as a measure of how much problem-specific knowledge is incorporated in the search algorithm.
(c) Calculations of and for a few examples of search problems.
That’s it. Dembski and Marks do not discuss how the target set might arise or be chosen, simply assuming that it is as constant as the search space. For a search problem to be in any way interesting and significant there must be some more structure available than just a set and a subset . Clearly, a target set might arise in many ways and in many settings it is necessary to consider a probabilistic model for both target set-membership and target set size rather than a constant target set. For example, in the Traveling Salesman Problem one considers a class of several problem instances, with different target sets, and attempts to find algorithms that work for well on average or even in the worst-case scenario. When searching a database, the size of the target set depends on the database query and on the content of the database. A good algorithm for database search works for several different target sets. The approach taken by Dembski and Marks suffers from the flaw that entirely structureless search problems are uninteresting and lack significance, and these properties carry over to their analysis of search problems.
Reference
W. Dembski and J. Marks II. Conservation of Information in Search: Measuring the Cost of Success. IEEE Trans. Sys. Man. Cybernetics A 39:1051 (2009)
This entry was posted on Wednesday, August 19th, 2009 at 18:01 and is filed under oil of snake. You can follow any responses to this entry through the RSS 2.0 feed.
Both comments and pings are currently closed.
5 Responses to Dembski and Marks publish trivial ID paper
LOL, this has taken off.. this is a bogus generated paper similar to the MIT computer paper generator.. I can’t believe people aren’t seeing right through this.. I guess when you use big enough words and a lot of mathematical symbols, people will believe anything. Kudos to whoever was able to get this out there.
[…] Dembski’s misrepresentation of the Weasel program, as he has misrepresented it yet again in a trivial non-id paper. The get some much needed perspective, read Joe Felsenstein’s excellent article (and its […]
[…] problem consisting of a search space and a distinguished target set (blogger reactions: 1, 2, 3, 4, 5, 7). From the discussion in the paper and two other articles it is clear that the […]

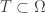
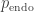






LOL, this has taken off.. this is a bogus generated paper similar to the MIT computer paper generator.. I can’t believe people aren’t seeing right through this.. I guess when you use big enough words and a lot of mathematical symbols, people will believe anything. Kudos to whoever was able to get this out there.
[…] The Metropolis Sampler […]
[…] Dembski’s misrepresentation of the Weasel program, as he has misrepresented it yet again in a trivial non-id paper. The get some much needed perspective, read Joe Felsenstein’s excellent article (and its […]
[…] problem consisting of a search space and a distinguished target set (blogger reactions: 1, 2, 3, 4, 5, 7). From the discussion in the paper and two other articles it is clear that the […]
On the contrary. The paper by D&M might be good groundwork to consider the questions posed here.
One can always ask further questions you know… No one thinks that further questions falsify an argument (well, except those with high negative bias).